- Non technical people can draft and iterate on prompts.
- You can deploy a new version of your prompt without deploying your code.
- You can track which prompt version for a specific generation.
- You can compare prompt versions to see which one performs better.
- You can compare and test multiple LLM providers.
- You can collaborate with the team.
- You can do online evaluation [coming soon].
Versioning
On thePrompts dashboard, you can see which prompts are present and running (Champion Version). By clicking on a prompt, you get to a page where you can see which versions of that prompt are saved. By clicking on a version number, you enter the Playground, where you can change this prompt, or promote this prompt template to the Champion Version.
Prompt Playground
The playground is an environment in which you can create, test, and debug prompts. You can access the playground via- The main menu. This allows you to create, test and save prompts from scratch.
- Prompts. This allows you to view, edit and test your prompt template and LLM settings and manage prompt versioning.
- LLM Generations. Via Generations you can access the playground with an individual generation from a real chat conversation. This allows you to debug a single generation of the LLM in context.
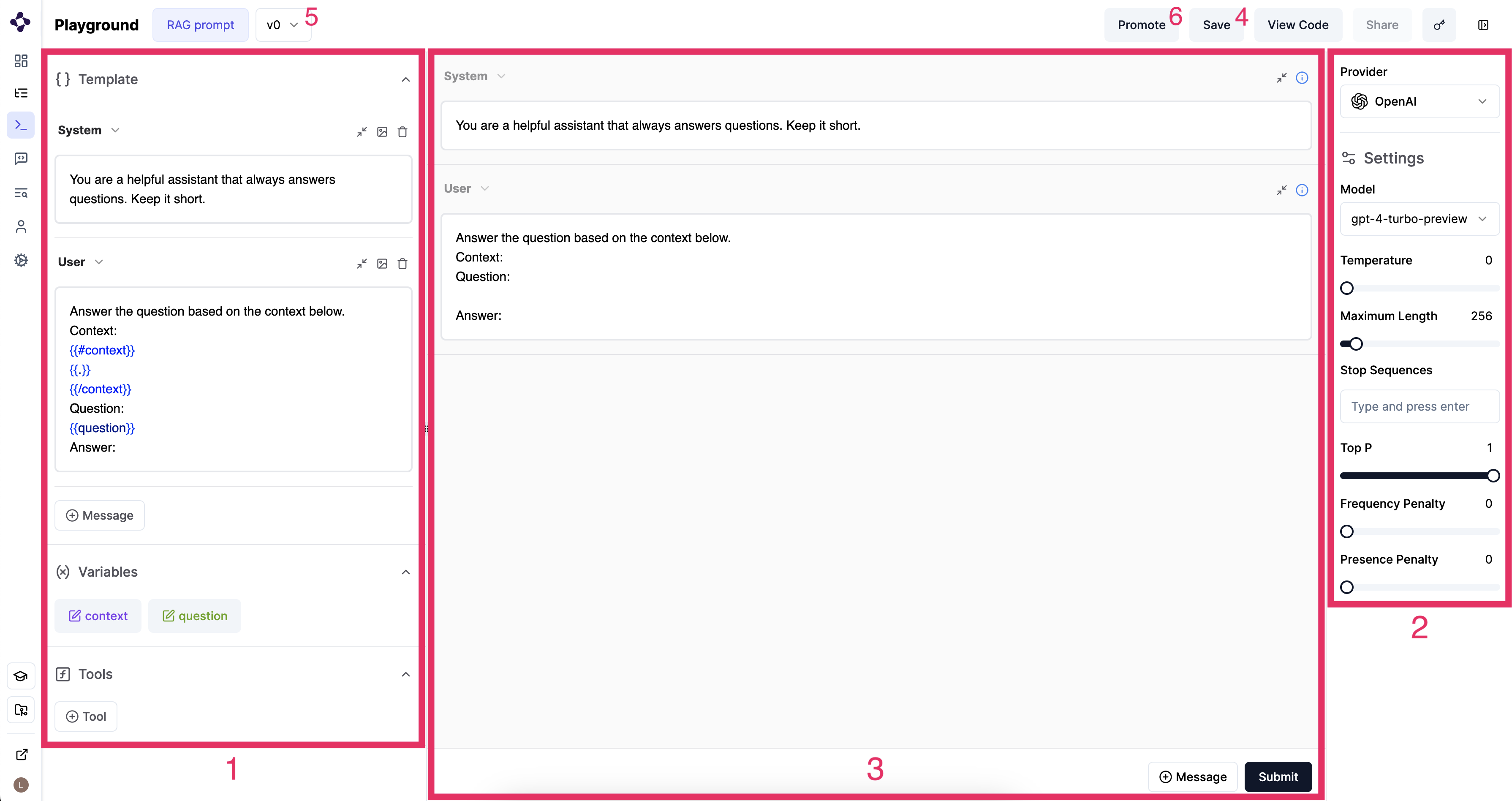
1. Design prompt templates
On the left hand side of the view you can create prompt templates (1).- In a
system messageyou give instructions about the role of the assistant. For example, you can say that the assistant should provide concise answers. - In
User, you give a format of the user query to the LLM. In this example, two variables are used. First, context documents are given, in a for-loop. The content of the variables can be defined below, but are usually defined in the code of the application. Then, the question that the user entered in the chatbot window is given. Assistantmessages are responses by the LLM.Toolmessages are responses by the tool or function.
Tools. The LLM model can detect when a specific function needs to be called based on the user’s input.
Formatting
The text and code in the prompt template is formatted according to the the Mustache prompt templating format. Tags are surrounded by “mustaches” or double curly brackets. With tags and mustaches, variables, sections, loops and functions can be declared. A variable is written like{{variable}}, and an if statement and for-loop is written like the following. If x is a boolean value, the section tag acts like an if conditional. When x is an array, this acts like a for each loop.
2. LLM settings
On the right side of the screen (2), you can set an LLM provider (for example OpenAI or Anthropic). You can change the following settings:- Model. Which model of the provider to use.
- Temperature. Control randomness. A lower temperature results in less random generations. As the temperature approaches zero, the model will become deterministic and repetitive.
- Maximum Length. Maximum length of tokens to generate. Requests can use op to 32,000 tokens, shared between prompt and completion. The exact limit varies per model.
- Stop Sequences. Use up to four sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
- Top P or Nucleas Sampling. Controlling diversity by how many possible words to consider. A high Top P will look at more possible words, even the less likely ones, which makes the generated text more diverse.
- Frequency Penalty. How much to penalize new tokes based on their existing frequency in the text so far. Decreases the model’s likelihood to repeat the sam line verbatim.
- Presence Penalty. How much to penalize new tokens based on whether they appear in the text so far. Increases the model’s likelihood to talk about new topics.
3. Try out & in-context debugging.
In the center of the screen (3), you can try out the settings and prompt template. Make sure you have an API key of the selected provided set (at the top right key icon). Then, you can send messages to the LLM using this template and settings. You can change things, and try again. If you accessed the playground via an LLM call, you get the conversation context which you can use to try out different settings. You can also use multimodality here. For example, you can upload an image in the chat.4. Save
Once you are happy with the template and settings, you can save the setup (4). When you save a new template, a screen will pop up with a diff comparison. In this changelog, like using Git, you can see what you have changed, before you save these changes.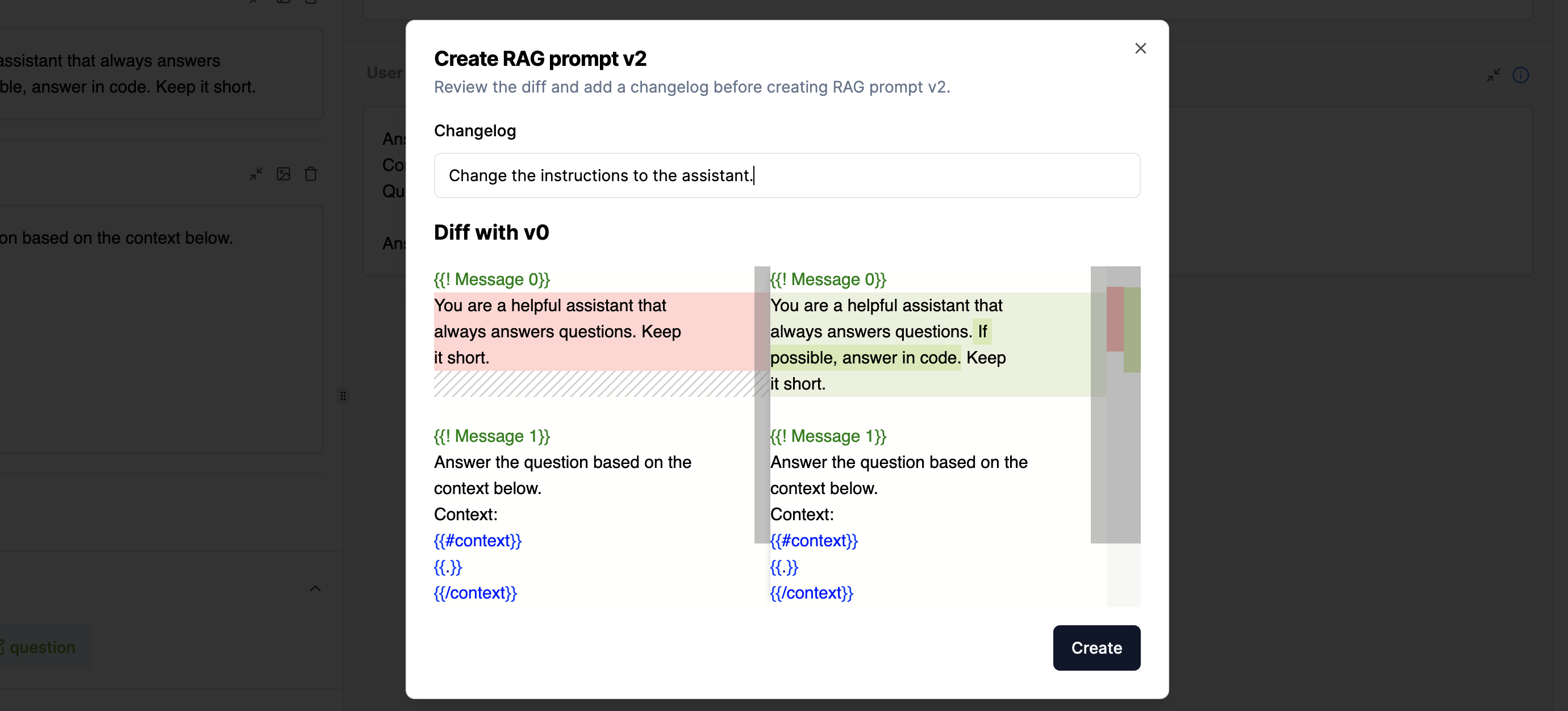
5. Promote
If you want to upgrade the version you opened in the Playground to the current version your application is using, you need toPromote the prompt template and settings. You do this by selecting the correct version (5), and clicking on the Promote button (6).